When it comes to running complex application workloads on Kubernetes two technologies standout — Helm and Kubernetes Operators. In this post we compare them and discuss how they actually complement each other towards solving problems of day-1 and day-2 operations when it comes to running complex application workloads on Kubernetes. We also present guidelines for creating Helm charts for Operators.
What is Helm?
The basic idea of Helm is to enable reusability of Kubernetes YAML artifacts through templatization. Helm allows defining Kubernetes YAMLs with marked up properties. The actual values for these properties are defined in a separate file. Helm takes the templatized YAMLs and the values file and merges them before deploying the merged YAMLs into a cluster. The package consisting of templatized Kubernetes YAMLs and the values file is called a ‘Helm chart’. Helm project has gained considerable popularity as it solves one of the key problems that enterprises face — creating custom YAMLs for deploying the same application workload with different settings, or deploying it in different environments (dev/test/prod).
What is a Kubernetes Operator?
The basic idea of a Kubernetes Operator is to extend the Kubernetes’s level-driven reconciliation loop and API set towards running stateful application workloads natively on Kubernetes. A Kubernetes Operator consists of Kubernetes Custom Resource(s) / API(s) and Kubernetes Custom Controller(s). The Custom Resources represent an API that takes declarative inputs on the workload being abstracted and the Custom Controller implements corresponding actions on the workload. Kubernetes Operators are typically implemented in a standard programming language (Golang, Python, Java, etc.). An Operator is packaged as a container image and is deployed in a Kubernetes cluster using Kubernetes YAMLs. Once deployed, new Custom Resources (e.g. Mysql, Cassandra, etc.) are available to the end users similar to built-in Resources (e.g. Pod, Service, etc.). This allows them to orchestrate their application workflows more effectively leveraging additional Custom Resources.
Day-1 vs. Day-2 operations
Helm and Operators represent two different phases in managing complex application workloads on Kubernetes. Helm’s primary focus is on the day-1 operation of deploying Kubernetes artifacts in a cluster. The ‘domain’ that it understands is that of Kubernetes YAMLs that are composed of available Kubernetes Resources / APIs. Operators, on the other hand, are primarily focused on addressing day-2 management tasks of stateful / complex workloads such as Postgres, Cassandra, Spark, Kafka, SSL Cert Mgmt etc. on Kubernetes.
Both these mechanisms are complementary to deploying and managing such workloads on Kubernetes. To Helm, Operator deployment YAMLs represent one of the artifact types that can be potentially templatized and deployed with different settings and in different environments. To an Operator developer, Helm represents a standard tool to package, distribute and install Operator deployment YAMLs without tie-in to any Kubernetes vendor or distribution. As an Operator developer, it is tremendously useful for your users if you create Helm chart for its deployment. Below are some guidelines that you should follow when creating such Operator Helm charts.
Guidelines for creating Operator Helm charts
Register CRDs in Helm chart (and not in Operator code)
As mentioned earlier, an Operator consists of one or more Custom Resources and associated Controller(s). In order for the Custom Resources to be recognized in a cluster, they need to be first registered in the cluster using Kubernetes’s meta API of ‘Custom Resource Definition (CRD)’. The CRD itself is a Kubernetes resource. Our first guideline is that registering the Custom Resources using CRDs should be done as Kubernetes YAML files in a Helm chart, rather than in Operator’s code (Golang/Python, etc.). The primary reason for this is that installing CRD YAML requires cluster-scope permission whereas an Operator Pod may not require cluster-scope permissions for its day-2 operations on an application workload. If you include CRD registration in your Operator’s code, then you will have to deploy your Operator Pod with cluster-scope permissions, which may come in the way of your security preferences. By defining CRD registration in Helm chart, you only need to give the Operator Pod those permissions that are necessary for it to perform the actual day-2 operations on the underlying application workload.
2. Make sure CRDs are getting installed prior to the Operator deployment
The second guideline is to define crd-install hook as part of the Operator Helm chart. What is this hook? ‘crd-install’ is a special annotation that you can add to your Helm chart’s CRD manifest. When installing a chart in a cluster, Helm installs any YAML manifests with this annotation before installing any other manifests of a chart. By adding this annotation you will ensure that the Custom Resources that your Operator works with are registered in the cluster before the Operator is deployed. This will prevent errors that happen if Operator starts running without its CRDs registered in the cluster. Note that in Helm 3.0, this hook is going away. Instead, CRDs are getting a special directory inside the charts directory.
3. Define Custom Resource validation rules in CRD YAML
Next guideline is about adding Custom Resource validation rules as part of CRD YAML. Kubernetes Custom Resources are designed to follow the Open API Spec. Additionally from Operator logic perspective, Custom Resource instances should have valid values for its defined Spec properties. You can define validity rules for the Custom Resource Spec properties as part of CRD YAML. These validation rules are used by Kubernetes machinery before a Custom Resource YAML reaches your Operator through one of the CRUD (Create, Read, Update, Delete) operations on the Custom Resource. This guideline helps prevent end user of the Custom Resource making unintentional errors while using it.
4. Use values.yaml or ConfigMaps for Operator configurables
Your Operator itself may need to be customized for different environments or even for different namespaces within a cluster. The customizations may range from small modifications, such as customizing the base MySQL image used by a MySQL Operator, to larger modifications such as installing different default set of plugins on different Moodle instances by a Moodle Operator. As mentioned earlier, Helm supports mechanisms of Spec property markers and Values.yaml file for templatization/customization. You can leverage these for small modifications that typically can be represented as singular properties in Operator deployment manifests. For supporting larger modifications to an Operator, consider passing the configuration data via ConfigMaps. The names of such ConfigMaps need to be passed to the Operator. For that you can use Helm’s property markers and Values.yaml file.
5. Add Platform-as-Code annotations to enable easy discovery and consumption of Operator’s Custom Resources
The last guideline that we have is to add ‘Platform-as-Code’ annotations on your Operator’s CRD YAML. There are two annotations that we recommend — ‘composition’ and ‘man’. The value of the ‘platform-as-code/composition’ annotation is listing of all Kubernetes built-in resources that are created by the Operator when the Custom Resource instance is created. The value of the ‘platform-as-code/man’ annotation is the name of a ConfigMap that packages ‘man page’ like usage information about the Custom Resource. Make sure to include this ConfigMap in your Operator’s Helm chart. These two annotations are part of our KubePlus API Add-on that simplifies discovery, binding and orchestration of Kubernetes Custom Resources to create platform workflows in typical multi-Operator environments.
Conclusion
Helm and Operators are complementary technologies. Helm is geared towards performing day-1 operations of templatization and deployment of Kubernetes YAMLs — in this case Operator deployment. Operator is geared towards handling day-2 operations of managing application workloads on Kubernetes. You will need both when running stateful / complex workloads on Kubernetes.
At CloudARK, we have been helping platform engineering teams build their custom platform stacks assembling multiple Operators to run their enterprise workloads. Our novel Platform-as-Code technology is designed to simplify workflow management in multi-Operator environments by bringing in consistency across Operators and simplifying consumption of Custom Resources towards defining required platform workflows. For this we have developed comprehensive Operator curation guidelines and open source Platform-as-Code tooling.
Reach out to us to find out how you too can build your Kubernetes Native platforms with Platform-as-Code approach.
In this article I will try to summarize my favorite tools for Kubernetes with special emphasis on the newest and lesser known tools which I think will become very popular.
This is just my personal list based on my experience but, in order to avoid biases, I will try to also mention alternatives to each tool so you can compare and decide based on your needs. I will keep this article as short as I can and I will try to provide links so you can explore more on your own. My goal is to answer the question: “How can I do X in Kubernetes?” by describing tools for different software development tasks.
K3D
K3D is my favorite way to run Kubernetes(K8s) clusters on my laptop. It is extremely lightweight and very fast. It is a wrapper around K3S using Docker. So, you only need Docker to run it and it has a very low resource usage. The only problem is that it is not fully K8s compliant, but this shouldn’t be an issue for local development. For test environments you can use other solutions. K3D is faster than Kind, but Kind is fully compliant.
Krew is an essential tool to manage Kubectlplugins, this is a must have for any K8s user. I won’t go into the details of the more than 145 plugins available but at least install kubens and kubectx.
Lens
Lens is an IDE for K8s for SREs, Ops and Developers. It works with any Kubernetes distribution: on-prem or in the cloud. It is fast, easy to use and provides real time observability. With Lens it is very easy to manage many clusters. This is a must have if you are a cluster operator.
Lens
Alternatives
K9sis an excellent choice for those who prefer a lightweight terminal alternative. K9s continually watches Kubernetes for changes and offers subsequent commands to interact with your observed resources.
Helm
Helm shouldn’t need an introduction, it is the most famous package manager for Kubernetes. And yes, you should use package managers in K8s, same as you use it in programming languages. Helm allows you to pack your application in Charts which abstract complex application into reusable simple components that are easy to define, install and update.
It also provides a powerful templating engine. Helm is mature, has lots of pre defined charts, great support and it is easy to use.
Alternatives
Kustomize is a newer and great alternative for helm which does not use a templating engine but an overlay engine where you have base definitions and overlays on top of them.
ArgoCD
I believe that GitOps is one of the best ideas of the last decade. In software development, we should use a single source of truth to track all the moving pieces required to build software and Git is a the perfect tool to do that. The idea is to have a Git repository that contains the application code and also declarative descriptions of the infrastructure(IaC) which represent the desired production environment state; and an automated process to make the desired environment match the described state in the repository.
GitOps: versioned CI/CD on top of declarative infrastructure. Stop scripting and start shipping.
Although with Terraform or similar tools you can have your infrastructure as code(IaC), this is not enough to be able to sync your desired state in Git with production. We need a way to continuous monitor the environments and make sure there is no configuration drift. With Terraform you will have to write scripts that run terraform apply and check if the status matches the Terraform state but this is tedious and hard to maintain.
Kubernetes has been build with the idea of control loops from the ground up, this means that Kubernetes is always watching the state of the cluster to make sure it matches the desired state, for example, that the number of replicas running matches the desired number of replicas. The idea of GitOps is to extend this to applications, so you can define your services as code, for example, by defining Helm Charts, and use a tool that leverages K8s capabilities to monitor the state of your App and adjust the cluster accordingly. That is, if update your code repo, or your helm chart the production cluster is also updated. This is true continuous deployment. The core principle is that application deployment and lifecycle management should be automated, auditable, and easy to understand.
For me this idea is revolutionary and if done properly, will enable organizations to focus more on features and less on writing scripts for automation. This concept can be extended to other areas of Software Development, for example, you can store your documentation in your code to track the history of changes and make sure the documentation is up to date; or track architectural decision using ADRs.
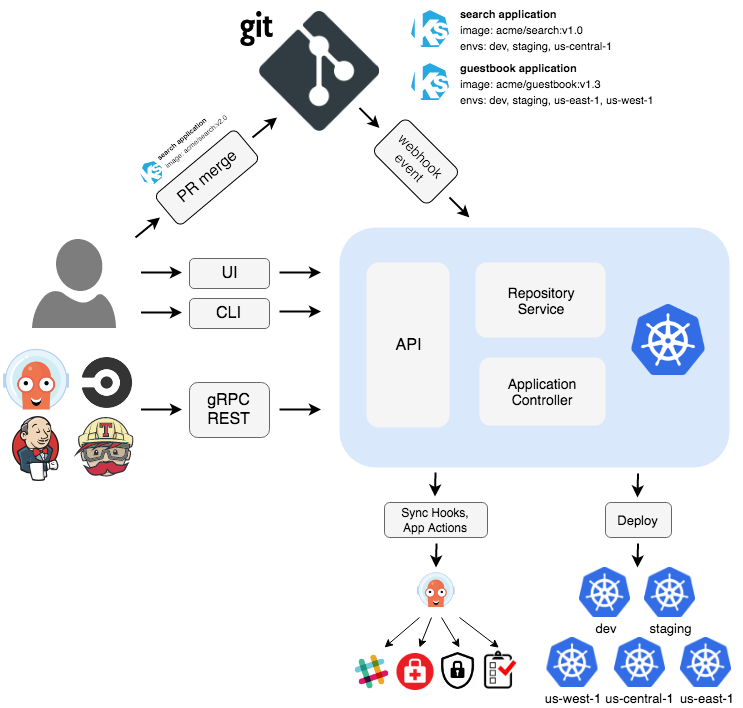
In my opinion, the best GitOps tool in Kubernetes is ArgoCD. You can read more about here. ArgoCD is part of the Argo ecosystem which includes some other great tools, some of which, we will discuss later.
With ArgoCD you can have each environment in a code repository where you define all the configuration for that environment. Argo CD automates the deployment of the desired application state in the specified target environments.
ArgoCD architecture
Argo CD is implemented as a kubernetes controller which continuously monitors running applications and compares the current, live state against the desired target state (as specified in the Git repo). Argo CD reports and visualizes the differences and can automatically or manually sync the live state back to the desired target state.
Alternatives
Flux which just released a new version with many improvements. It offers very similar functionality.
Argo Workflows and Argo Events
In Kubernetes, you may also need to run batch jobs or complex workflows. This could be part of your data pipeline, asynchronous processes or even CI/CD. On top of that, you may need to run even driven microservices that react to certain events like a file was uploaded or a message was sent to a queue. For all of this, we have Argo Workflows and Argo Events.
Although they are separate projects, they tend to be deployed together.
Argo Workflows is an orchestrationengine similar to Apache Airflow but native to Kubernetes. It uses custom CRDs to define complex workflows using steps or DAGs using YAML which feels more natural in K8s. It has an nice UI, retries mechanisms, cron based jobs, inputs and outputs tacking and much more. You can use it to orchestrate data pipelines, batch jobs and much more.
Sometimes, you may want to integrate your pipelines with Async services like stream engines like Kafka, queues, webhooks or deep storage services. For example, you may want to react to events like a file uploaded to S3. For this, you will use Argo Events.
Argo Events
These two tools combines provide an easy and powerful solution for all your pipelines needs including CI/CD pipelines which will allow you to run your CI/CD pipelines natively in Kubernetes.
We just saw how we can run Kubernetes native CI/CD pipelines using Argo Workflows. One common task is to build Docker images, this is usually tedious in Kubernetes since the build process actually runs on a container itself and you need to use workarounds to use the Docker engine of the host.
The bottom line is that you shouldn’t use Docker to build your images: use Kanico instead. Kaniko doesn’t depend on a Docker daemon and executes each command within a Dockerfile completely in userspace. This enables building container images in environments that can’t easily or securely run a Docker daemon, such as a standard Kubernetes cluster. This removes all the issues regarding building images inside a K8s cluster.
Istio
Istio is the most famous service mesh on the market, it is open source and very popular. I won’t go into details regarding what a service mesh is because it is a huge topic, but if you are building microservices, and probably you should, then you will need a service mesh to manage the communication, observability, error handling, security and all of the other cross cutting aspects that come as part of the microservice architecture. Instead of polluting the code of each microservice with duplicate logic, leverage the service mesh to do it for you.
Istio Architecture
In short, a service mesh is a dedicated infrastructure layer that you can add to your applications. It allows you to transparently add capabilities like observability, traffic management, and security, without adding them to your own code.
Istio if used to run microseconds and although you can run Istio and use microservices anywhere, Kubernetes has been proven over and over again as the best platform to run them. Istio can also extend your K8s cluster to other services such as VMs allowing you to have Hybrid environments which are extremely useful when migrating to Kubernetes.
Consul is a service mesh built for any runtime and cloud provider, so it works great for hybrid deployments across K8s and cloud providers. It is a great choice if not all your workloads run on Kubernetes.
Argo Rollouts
We mentioned already that you can use Kubernetes to run your CI/CD pipeline using Argo Workflows or a similar tools using Kanico to build your images. The next logical step is to continue and do continuous deployments. This is is extremely challenging to do in a real word scenario due to the high risk involved, that’s why most companies just do continuous delivery, which means that they have the automation in place but they still have manual approvals and verification, this manual step is cause by the fact that the team cannot fully trust their automation.
So how do you build that trust to be able to get rid of all the scripts and fully automate everything from source code all the way to production? The answer is: observability. You need to focus the resources more on metrics and gather all the data needed to accurately represent the state of your application. The goal is to use a set of metrics to build that trust. If you have all the data in Prometheus then you can automate the deployment because you can automate the progressive roll out of your application based on those metrics.
In short, you need more advanced deployment techniques than what K8s offers out of the box which are Rolling Updates. We need progressive delivery using canary deployments. The goal is to progressively route traffic to the new version of an application, wait for metrics to be collected, analyze them and match them against pre define rules. If everything is okay, we increase the traffic; if there are any issues we roll back the deployment.
To do this in Kubernetes, you can use Argo Rollouts which offers Canary releases and much more.
Argo Rollouts is a Kubernetes controller and set of CRDs which provide advanced deployment capabilities such as blue-green, canary, canary analysis, experimentation, and progressive delivery features to Kubernetes.
Although Service Meshes like Istio provide Canary Releases, Argo Rollouts makes this process much easier and developer centric since it was built specifically for this purpose. On top of that Argo Rollouts can be integrated with any service mesh.
Argo Rollouts Features:
Blue-Green update strategy
Canary update strategy
Fine-grained, weighted traffic shifting
Automated rollbacks and promotions or Manual judgement
Customizable metric queries and analysis of business KPIs
Ingress controller integration: NGINX, ALB
Service Mesh integration: Istio, Linkerd, SMI
Metric provider integration: Prometheus, Wavefront, Kayenta, Web, Kubernetes Jobs
Alternatives
Istioas a service mesh for canary releases. Istio is much more than a progressive delivery tool, it is a full service mesh. Istio does not automate the deployment, Argo Rollouts can integrate with Istio to achieve this.
Flagger is very similar to Argo Rollouts and it very well integrated with Flux, so if your ar using Flux consider Flagger.
Spinnaker was the first continuous delivery tool for Kubernetes, it has many features but it is a bit more complicated to use and set up.
Crossplane
Crossplane is my new favorite K8s tool, I’m very exited about this project because it brings to Kubernetes a critical missing piece: manage 3rd party services as if they were K8s resources. This means, that you can provision a cloud provider databases such AWSRDS or GCPCloud SQL like you would provision a database in K8s, using K8s resources defined in YAML.
With Crossplane, there is no need to separate infrastructure and code using different tools and methodologies. You can define everything using K8s resources. This way, you don’t need to learn new tools such as Terraform and keep them separately.
Crossplane is an open source Kubernetes add-on that enables platform teams to assemble infrastructure from multiple vendors, and expose higher level self-service APIs for application teams to consume, without having to write any code.
Crossplane extends your Kubernetes cluster, providing you with CRDs for any infrastructure or managed cloud service. Furthermore, it allows you to fully implement continuous deployment because contrary to other tools such Terraform, Crossplane uses existing K8s capabilities such as control loops to continuously watch your cluster and detect any configuration drifting acting on it automatically. For example, if you define a managed database instance and someone manually change it, Crossplane will automatically detect the issue and set it back to the previous value. This enforces infrastructure as code and GitOps principles. Crossplane works great with Argo CD which can watch the source code and make sure your code repo is the single source of truth and any changes in the code are propagated to the cluster and also external cloud services. Without Crossplane you could only implement GitOps in your K8s services but not your cloud services without using a separate process, now you can do this, which is awesome.
Alternatives
Terraform which is the most famous IaC tool but it is not native to K8s, requires new skills and does not automatically watches from configuration drifts.
Pulumi which is a Terraform alternative which works using programming languages that can be tested and understood by developers.
Knative
If you develop your applications in the cloud you probably have used some Serverless technologies such as AWS Lambdawhich is an event driven paradigm known as FaaS.
I already talked about Serverless in the past, so check my previous article to know more about this. The problem with Serverless is that it is tightly coupled to the cloud provider since the provider can create a great ecosystem for event driven applications.
For Kubernetes, if you want to run functions as code and use an event driven architecture, your best choice is Knative. Knative is build to run functions on Kubernetes creating an abstraction on top of a Pod.
Features:
Focused API with higher level abstractions for common app use-cases.
Stand up a scalable, secure, stateless service in seconds.
Loosely coupled features let you use the pieces you need.
Pluggable components let you bring your own logging and monitoring, networking, and service mesh.
Knative is portable: run it anywhere Kubernetes runs, never worry about vendor lock-in.
Idiomatic developer experience, supporting common patterns such as GitOps, DockerOps, ManualOps.
Knative can be used with common tools and frameworks such as Django, Ruby on Rails, Spring, and many more.
Alternatives
Argo Events provide an event-driven workflow engine for Kubernetes that can integrate with cloud engines such as AWS Lambda. It is not FaaS but provides an event driven architecture to Kubernetes.
kyverno
Kubernetes provides great flexibility in order to empower agile autonomous teams but with great power comes great responsibility. There has to be a set of best practices and rules to ensure a consistent and cohesive way to deploy and manage workloads which are compliant with the companies policies and security requirements.
There are several tools to enable this but none were native to Kubernetes… until now. Kyverno is a policy engine designed for Kubernetes, policies are managed as Kubernetes resources and no new language is required to write policies. Kyverno policies can validate, mutate, and generate Kubernetes resources.
A Kyverno policy is a collection of rules. Each rule consists of a match clause, an optional exclude clause, and one of a validate, mutate, or generate clause. A rule definition can contain only a single validate, mutate, or generate child node.
You can apply any kind of policy regarding best practices, networking or security. For example, you can enforce that all your service have labels or all containers run as non root. You can check some policy examples here. Policies can be applied to the whole cluster or to a given namespace. You can also choose if you just want to audit the policies or enforce them blocking users from deploying resources.
Alternatives
Open Policy Agent is a famous cloud native policy-based control engine. It used its own declarative language and it works in many environments, not only on Kubernetes. It is more difficult to manage than Kyvernobut more powerful.
Kubevela
One problem with Kubernetes is that developers need to know and understand very well the platform and the cluster configuration. Many would argue that the level of abstraction in K8s is too low and this causes a lot of friction for developers who just want to focus on writing and shipping applications.
The Open Application Model (OAM) was created to overcome this problem. The idea is to create a higher level of abstraction around applications which is independent of the underlying runtime. You can read the spec here.
Focused on application rather than container or orchestrator, Open Application Model [OAM] brings modular, extensible, and portable design for modeling application deployment with higher level yet consistent API.
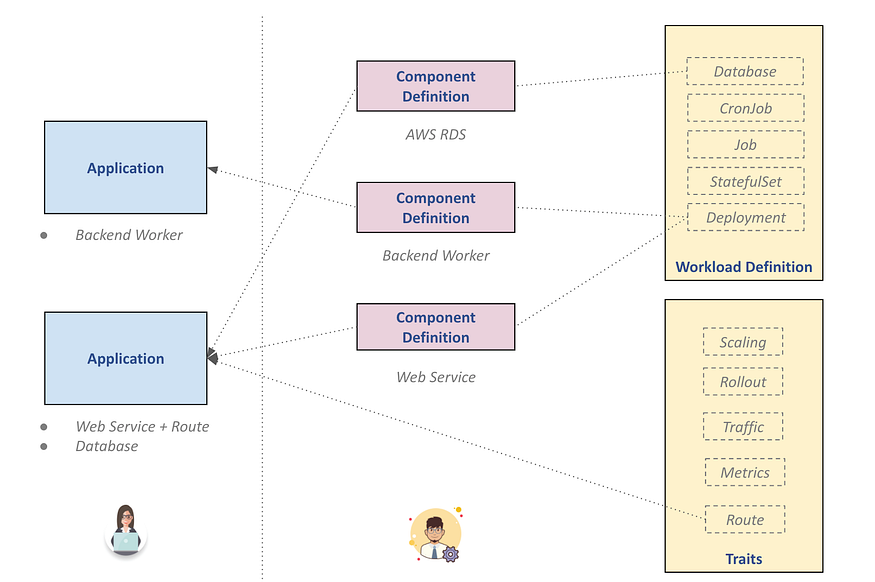
Kubevela is an implementation of the OAM model. KubeVela is runtime agnostic, natively extensible, yet most importantly, application-centric . In Kubevela applications are first class citizens implemented as Kubernetes resources. There is a distinction between cluster operators(Platform Team) and developers (Application Team). Cluster operators manage the cluster and the different environments by defining components(deployable/provisionable entities that compose your application like helm charts) and traits. Developers define applications by assembling components and traits.
Platform Team: Model and manage platform capabilities as components or traits, together with target environments specifications. Application Team: Choose a environment, assemble the application with components and traits per needs, and deploy it to target environment.
KubeVela is a Cloud Native Computing Foundation sandbox project and although it is still in its infancy, it can change the way we use Kubernetes in the near future allowing developers to focus on applications without being Kubernetes experts. However, I do have some concerns regarding the applicability of the OAM in the real world since some services like system applications, ML or big data processes depend considerably on low level details which could be tricky to incorporate in the OAM model.
Alternatives
Shipa follows a similar approach enabling platform and developer teams to work together to easily deploy application to Kubernetes.
Snyk
A very important aspect in any development process is Security, this has always been an issue for Kubernetes since companies who wanted to migrate to Kubernetes couldn’t easily implement their current security principles.
Snyk tries to mitigate this by providing a security framework that can easily integrate with Kubernetes. It can detect vulnerabilities in container images, your code, open source projects and much more.
Velero
If you run your workload in Kubernetes and you use volumes to store data, you need to create and manage backups. Velero provides a simple backup/restore process, disaster recovery mechanisms and data migrations.
Velero Functionality
Unlike other tools which directly access the Kubernetes etcd database to perform backups and restores, Velero uses the Kubernetes API to capture the state of cluster resources and to restore them when necessary. Additionally, Velero enables you to backup and restore your application persistent data alongside the configurations.
Schema Hero
Another common process in software development is to manage schema evolution when using relational databases.
SchemaHero is an open-source database schema migration tool that converts a schema definition into migration scripts that can be applied in any environment. It uses Kubernetes declarative nature to manage database schema migrations. You just specify the desired state and SchemaHero manages the rest.
Alternatives
LiquidBase is the most famous alternative. It is more difficult to use and it’s not Kubernetes native but it has more features.
Bitnami Sealed Secrets
We already cover many GitOps tools such as ArgoCD. Our goal is to keep everything in Git and use Kubernetes declarative nature to keep the environments in sync. We just saw how we can (and we should) keep our source of truth in Git and have automated processes handle the configuration changes.
One thing that it was usually hard to keep in Git were secrets such DB passwords or API keys, this is because you should never store secrets in your code repository. One common solution is to use an external vault such as AWS Secret Manageror HashiCorpVaultto store the secrets but this creates a lot of friction since you need to have a separate process to handle secrets. Ideally, we would like a way to safely store secrets in Git just like any other resource.
Sealed Secrets were created to overcome this issue allowing you to store your sensitive data in Git by using strong encryption. Bitnami Sealed Secrets integrate natively in Kubernetes allowing you to decrypt the secrets only by the Kubernetes controller running in Kubernetes and no one else. The controller will decrypt the data and create native K8s secrets which are safely stored. This enables us to store absolutely everything as code in our repo allowing us to perform continuous deployment safely without any external dependencies.
Sealed Secrets is composed of two parts:
A cluster-side controller
A client-side utility: kubeseal
The kubeseal utility uses asymmetric crypto to encrypt secrets that only the controller can decrypt. These encrypted secrets are encoded in a SealedSecret K8s resource that you can store in Git.
Many companies use multi tenancy to manage different customers. This is quite common in software development but difficult to implement in Kubernetes. Namespaces are a great way to create logical partitions of the cluster as isolated slices but this is not enough in order to securely isolate customers, we need to enforce network policies, quotas and more. You can create network policies and rules per name space but this is a tedious process that it is difficult to scale. Also, tenants will not able to use more than one namespace which is a big limitation.
Hierarchical Namespaces were created to overcome some of these issues. The idea is to have a parent namespace per tenant with common network policies and quotas for the tenants and allow the creation of child namespaces. This is a great improvement but it does not have native support for a tenant in terms of security and governance. Furthermore, it hasn’t reach production status yet but version 1.0 is expected to be release in the next months.
A common approach to currently solve this, is to create a cluster per customer, this is secure and provides everything a tenant will need but this is hard to manage and very expensive.
Capsule is a tool which provides native Kubernetes support for multiple tenants within a single cluster. With Capsule, you can have a single cluster for all your tenants. Capsule will provide an “almost” native experience for the tenants(with some minor restrictions) who will be able to create multiple namespaces and use the cluster as it was entirely available for them hiding the fact that the cluster is actually shared.
Capsule architecture
In a single cluster, the Capsule Controller aggregates multiple namespaces in a lightweight Kubernetes abstraction called Tenant, which is a grouping of Kubernetes Namespaces. Within each tenant, users are free to create their namespaces and share all the assigned resources while the Policy Engine keeps the different tenants isolated from each other.
The Network and Security Policies, Resource Quota, Limit Ranges, RBAC, and other policies defined at the tenant level are automatically inherited by all the namespaces in the tenant similar to Hierarchical Namespaces. Then users are free to operate their tenants in autonomy, without the intervention of the cluster administrator. Capsule is GitOps ready since it is declarative and all the configuration can be stored in Git.
vCluster
VCluster goes one step further in terms of multi tenancy, it offers virtual clusters inside a Kubernetes cluster. Each cluster runs on a regular namespace and it is fully isolated. Virtual clusters have their own API server and a separate data store, so every Kubernetes object you create in the vcluster only exists inside the vcluster. Also, you can use kube context with virtual clusters to use them like regular clusters.
As long as you can create a deployment inside a single namespace, you will be able to create a virtual cluster and become admin of this virtual cluster, tenants can create namespaces, install CRDs, configure permissions and much more.
vCluster uses k3s as its API server to make virtual clusters super lightweight and cost-efficient; and since k3s clusters are 100% compliant, virtual clusters are 100% compliant as well. vclusters are super lightweight (1 pod), consume very few resources and run on any Kubernetes cluster without requiring privileged access to the underlying cluster. Compared to Capsule, it does use a bit more resources but it offer more flexibility since multi tenancy is just one of the use cases.
vCluster use cases
Other Tools
kube-burner is used for stress testing. It provides metrics and alerts.
kubewatch is used for monitoring but mainly focus on push notifications based on Kubernetes events like resource creation or deletion. It can integrate with many tools like Slack.
kube-fledged is a Kubernetes add-on for creating and managing a cache of container images directly on the worker nodes of a Kubernetes cluster. As a result, application pods start almost instantly, since the images need not be pulled from the registry.
Conclusion
In this article we have reviewed my favorite Kubernetes tools. I focused on Open Source projects that can be incorporated in any Kubernetes distribution. I didn’t cover comercial solutions such as OpenShift or Cloud Providers Add-Ons since I wanted to keep i generic, but I do encourage to explore what your cloud provider can offer you if you run Kubernetes on the cloud or using a comercial tool.
My goal is to show you that you can do everything you do on-prem in Kubernetes. I also focused more in less known tools which I think may have a lot of potential such Crossplane, Argo Rollouts or Kubevela. The tools that I’m more excited about are vCluster, Crossplane and ArgoCD/Workflows.
Feel free to get in touch if you have any questions or need any advice.
Last Friday, one of my colleagues approached me and asked a question about how to exec a command in a pod with client-go. I didn’t know the answer and I noticed that I had never thought about the mechanism in “kubectl exec”. I had some ideas about how it should be, but I wasn’t 100% sure. I noted the topic to check again and I have learnt a lot after reading some blogs, docs and source codes. In this blog post, I am going to share my understanding and findings.
Setup
I cloned https://github.com/ecomm-integration-ballerina/kubernetes-cluster in order to create a k8s cluster in my MacBook. I fixed IP addresses of the nodes in kubelet configurations since the default configuration didn’t let me run kubectl exec. You can find the root cause here.
Any machine = my MacBook
IP of master node = 192.168.205.10
IP of worker node = 192.168.205.11
API server port = 6443
Components
kubectl exec process: When we run “kubectl exec …” in a machine, a process starts. You can run it in any machine which has an access to k8s api server.
api server: Component on the master that exposes the Kubernetes API. It is the front-end for the Kubernetes control plane.
kubelet: An agent that runs on each node in the cluster. It makes sure that containers are running in a pod.
container runtime: The software that is responsible for running containers. Examples: docker, cri-o, containerd…
kernel: kernel of the OS in the worker node which is responsible to manage processes.
target container: A container which is a part of a pod and which is running on one of the worker nodes.
Findings
1. Activities in Client Side
Create a pod in default namespace// any machine $ kubectl run exec-test-nginx --image=nginx
Then run an exec command and sleep 5000 to make observation// any machine $ kubectl exec -it exec-test-nginx-6558988d5-fgxgg -- sh # sleep 5000
We can observe the kubectl process (pid=8507 in this case)// any machine $ ps -ef |grep kubectl 501 8507 8409 0 7:19PM ttys000 0:00.13 kubectl exec -it exec-test-nginx-6558988d5-fgxgg -- sh
When we check network activities of the process, we can see that it has some connections to api-server (192.168.205.10.6443)// any machine $ netstat -atnv |grep 8507 tcp4 0 0 192.168.205.1.51673 192.168.205.10.6443 ESTABLISHED 131072 131768 8507 0 0x0102 0x00000020 tcp4 0 0 192.168.205.1.51672 192.168.205.10.6443 ESTABLISHED 131072 131768 8507 0 0x0102 0x00000028
Let’s check the code. kubectl creates a POST request with subresource exec and sends a rest request. req := restClient.Post(). Resource(“pods”). Name(pod.Name). Namespace(pod.Namespace). SubResource(“exec”) req.VersionedParams(&corev1.PodExecOptions{ Container: containerName, Command: p.Command, Stdin: p.Stdin, Stdout: p.Out != nil, Stderr: p.ErrOut != nil, TTY: t.Raw, }, scheme.ParameterCodec)
We can observe the request in api-server side as well.handler.go:143] kube-apiserver: POST "/api/v1/namespaces/default/pods/exec-test-nginx-6558988d5-fgxgg/exec" satisfied by gorestful with webservice /api/v1 upgradeaware.go:261] Connecting to backend proxy (intercepting redirects) https://192.168.205.11:10250/exec/default/exec-test-nginx-6558988d5-fgxgg/exec-test-nginx?command=sh&input=1&output=1&tty=1 Headers: map[Connection:[Upgrade] Content-Length:[0] Upgrade:[SPDY/3.1] User-Agent:[kubectl/v1.12.10 (darwin/amd64) kubernetes/e3c1340] X-Forwarded-For:[192.168.205.1] X-Stream-Protocol-Version:[v4.channel.k8s.io v3.channel.k8s.io v2.channel.k8s.io channel.k8s.io]] Notice that the http request includes a protocol upgrade request. SPDY allows for separate stdin/stdout/stderr/spdy-error “streams” to be multiplexed over a single TCP connection.
Api server receives the request and binds it into a PodExecOptions// PodExecOptions is the query options to a Pod’s remote exec call type PodExecOptions struct { metav1.TypeMeta
// Stdin if true indicates that stdin is to be redirected for the exec call Stdin bool
// Stdout if true indicates that stdout is to be redirected for the exec call Stdout bool
// Stderr if true indicates that stderr is to be redirected for the exec call Stderr bool
// TTY if true indicates that a tty will be allocated for the exec call TTY bool
// Container in which to execute the command. Container string
To be able to take necessary actions, api-server needs to know which location it should contact.// ExecLocation returns the exec URL for a pod container. If opts.Container is blank // and only one container is present in the pod, that container is used. func ExecLocation( getter ResourceGetter, connInfo client.ConnectionInfoGetter, ctx context.Context, name string, opts *api.PodExecOptions, ) (*url.URL, http.RoundTripper, error) { return streamLocation(getter, connInfo, ctx, name, opts, opts.Container, “exec”) }This Gist brought to you by gist-it.view rawpkg/registry/core/pod/strategy.go Of course the endpoint is derived from node info. nodeName := types.NodeName(pod.Spec.NodeName) if len(nodeName) == 0 { // If pod has not been assigned a host, return an empty location return nil, nil, errors.NewBadRequest(fmt.Sprintf(“pod %s does not have a host assigned”, name)) } nodeInfo, err := connInfo.GetConnectionInfo(ctx, nodeName)This Gist brought to you by gist-it.view rawpkg/registry/core/pod/strategy.go GOTCHA! KUBELET HAS A PORT (node.Status.DaemonEndpoints.KubeletEndpoint.Port) TO WHICH API-SERVER CAN CONNECT.// GetConnectionInfo retrieves connection info from the status of a Node API object. func (k *NodeConnectionInfoGetter) GetConnectionInfo(ctx context.Context, nodeName types.NodeName) (*ConnectionInfo, error) { node, err := k.nodes.Get(ctx, string(nodeName), metav1.GetOptions{}) if err != nil { return nil, err }
// Find a kubelet-reported address, using preferred address type host, err := nodeutil.GetPreferredNodeAddress(node, k.preferredAddressTypes) if err != nil { return nil, err }
// Use the kubelet-reported port, if present port := int(node.Status.DaemonEndpoints.KubeletEndpoint.Port) if port <= 0 { port = k.defaultPort }
return &ConnectionInfo{ Scheme: k.scheme, Hostname: host, Port: strconv.Itoa(port), Transport: k.transport, }, nil }This Gist brought to you by gist-it.view rawpkg/kubelet/client/kubelet_client.go Master-Node Communication > Master to Cluster > apiserver to kubeletThese connections terminate at the kubelet’s HTTPS endpoint. By default, the apiserver does not verify the kubelet’s serving certificate, which makes the connection subject to man-in-the-middle attacks, and unsafe to run over untrusted and/or public networks.
Now, api server knows the endpoint and it opens a connections.// Connect returns a handler for the pod exec proxy func (r *ExecREST) Connect(ctx context.Context, name string, opts runtime.Object, responder rest.Responder) (http.Handler, error) { execOpts, ok := opts.(*api.PodExecOptions) if !ok { return nil, fmt.Errorf(“invalid options object: %#v”, opts) } location, transport, err := pod.ExecLocation(r.Store, r.KubeletConn, ctx, name, execOpts) if err != nil { return nil, err } return newThrottledUpgradeAwareProxyHandler(location, transport, false, true, true, responder), nil }This Gist brought to you by gist-it.view rawpkg/registry/core/pod/rest/subresources.go
Let’s check what is going on the master node.
First, learn the ip of the worker node. It is 192.168.205.11 in this case.
// any machine
$ kubectl get nodes k8s-node-1 -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-node-1 Ready <none> 9h v1.15.3 192.168.205.11 <none> Ubuntu 16.04.6 LTS 4.4.0-159-generic docker://17.3.3
Then get the kubelet port. It is 10250 in this case.
// any machine
$ kubectl get nodes k8s-node-1 -o jsonpath='{.status.daemonEndpoints.kubeletEndpoint}'
map[Port:10250]
Then check the network. Is there a connection to worker node(192.168.205.11)? THE CONNECTİON IS THERE. When I kill the exec process, it disappears so I know it is set by api-server because of my exec command.
kubelet has a daemon which serves an api over a port for api-server requests.// Server is the library interface to serve the stream requests. type Server interface { http.Handler
// Get the serving URL for the requests. // Requests must not be nil. Responses may be nil iff an error is returned. GetExec(*runtimeapi.ExecRequest) (*runtimeapi.ExecResponse, error) GetAttach(req *runtimeapi.AttachRequest) (*runtimeapi.AttachResponse, error) GetPortForward(*runtimeapi.PortForwardRequest) (*runtimeapi.PortForwardResponse, error)
// Start the server. // addr is the address to serve on (address:port) stayUp indicates whether the server should // listen until Stop() is called, or automatically stop after all expected connections are // closed. Calling Get{Exec,Attach,PortForward} increments the expected connection count. // Function does not return until the server is stopped. Start(stayUp bool) error // Stop the server, and terminate any open connections. Stop() error }This Gist brought to you by gist-it.view rawpkg/kubelet/server/streaming/server.go
kubelet computes a response endpoint for exec requests.func (s *server) GetExec(req *runtimeapi.ExecRequest) (*runtimeapi.ExecResponse, error) { if err := validateExecRequest(req); err != nil { return nil, err } token, err := s.cache.Insert(req) if err != nil { return nil, err } return &runtimeapi.ExecResponse{ Url: s.buildURL(“exec”, token), }, nil }This Gist brought to you by gist-it.view rawpkg/kubelet/server/streaming/server.go
Don’t confuse. It doesn’t return the result of the command. It returns an endpoint for communication.
type ExecResponse struct { // Fully qualified URL of the exec streaming server. Url string `protobuf:"bytes,1,opt,name=url,proto3" json:"url,omitempty"` XXX_NoUnkeyedLiteral struct{} `json:"-"` XXX_sizecache int32 `json:"-"` }
kubelet implements RuntimeServiceClient interface which is part of Container Runtime Interface.
// For semantics around ctx use and closing/ending streaming RPCs, please refer to https://godoc.org/google.golang.org/grpc#ClientConn.NewStream. type RuntimeServiceClient interface { // Version returns the runtime name, runtime version, and runtime API version. Version(ctx context.Context, in *VersionRequest, opts ...grpc.CallOption) (*VersionResponse, error) // RunPodSandbox creates and starts a pod-level sandbox. Runtimes must ensure // the sandbox is in the ready state on success. RunPodSandbox(ctx context.Context, in *RunPodSandboxRequest, opts ...grpc.CallOption) (*RunPodSandboxResponse, error) // StopPodSandbox stops any running process that is part of the sandbox and // reclaims network resources (e.g., IP addresses) allocated to the sandbox. // If there are any running containers in the sandbox, they must be forcibly // terminated. // This call is idempotent, and must not return an error if all relevant // resources have already been reclaimed. kubelet will call StopPodSandbox // at least once before calling RemovePodSandbox. It will also attempt to // reclaim resources eagerly, as soon as a sandbox is not needed. Hence, // multiple StopPodSandbox calls are expected. StopPodSandbox(ctx context.Context, in *StopPodSandboxRequest, opts ...grpc.CallOption) (*StopPodSandboxResponse, error) // RemovePodSandbox removes the sandbox. If there are any running containers // in the sandbox, they must be forcibly terminated and removed. // This call is idempotent, and must not return an error if the sandbox has // already been removed. RemovePodSandbox(ctx context.Context, in *RemovePodSandboxRequest, opts ...grpc.CallOption) (*RemovePodSandboxResponse, error) // PodSandboxStatus returns the status of the PodSandbox. If the PodSandbox is not // present, returns an error. PodSandboxStatus(ctx context.Context, in *PodSandboxStatusRequest, opts ...grpc.CallOption) (*PodSandboxStatusResponse, error) // ListPodSandbox returns a list of PodSandboxes. ListPodSandbox(ctx context.Context, in *ListPodSandboxRequest, opts ...grpc.CallOption) (*ListPodSandboxResponse, error) // CreateContainer creates a new container in specified PodSandbox CreateContainer(ctx context.Context, in *CreateContainerRequest, opts ...grpc.CallOption) (*CreateContainerResponse, error) // StartContainer starts the container. StartContainer(ctx context.Context, in *StartContainerRequest, opts ...grpc.CallOption) (*StartContainerResponse, error) // StopContainer stops a running container with a grace period (i.e., timeout). // This call is idempotent, and must not return an error if the container has // already been stopped. // TODO: what must the runtime do after the grace period is reached? StopContainer(ctx context.Context, in *StopContainerRequest, opts ...grpc.CallOption) (*StopContainerResponse, error) // RemoveContainer removes the container. If the container is running, the // container must be forcibly removed. // This call is idempotent, and must not return an error if the container has // already been removed. RemoveContainer(ctx context.Context, in *RemoveContainerRequest, opts ...grpc.CallOption) (*RemoveContainerResponse, error) // ListContainers lists all containers by filters. ListContainers(ctx context.Context, in *ListContainersRequest, opts ...grpc.CallOption) (*ListContainersResponse, error) // ContainerStatus returns status of the container. If the container is not // present, returns an error. ContainerStatus(ctx context.Context, in *ContainerStatusRequest, opts ...grpc.CallOption) (*ContainerStatusResponse, error) // UpdateContainerResources updates ContainerConfig of the container. UpdateContainerResources(ctx context.Context, in *UpdateContainerResourcesRequest, opts ...grpc.CallOption) (*UpdateContainerResourcesResponse, error) // ReopenContainerLog asks runtime to reopen the stdout/stderr log file // for the container. This is often called after the log file has been // rotated. If the container is not running, container runtime can choose // to either create a new log file and return nil, or return an error. // Once it returns error, new container log file MUST NOT be created. ReopenContainerLog(ctx context.Context, in *ReopenContainerLogRequest, opts ...grpc.CallOption) (*ReopenContainerLogResponse, error) // ExecSync runs a command in a container synchronously. ExecSync(ctx context.Context, in *ExecSyncRequest, opts ...grpc.CallOption) (*ExecSyncResponse, error) // Exec prepares a streaming endpoint to execute a command in the container. Exec(ctx context.Context, in *ExecRequest, opts ...grpc.CallOption) (*ExecResponse, error) // Attach prepares a streaming endpoint to attach to a running container. Attach(ctx context.Context, in *AttachRequest, opts ...grpc.CallOption) (*AttachResponse, error) // PortForward prepares a streaming endpoint to forward ports from a PodSandbox. PortForward(ctx context.Context, in *PortForwardRequest, opts ...grpc.CallOption) (*PortForwardResponse, error) // ContainerStats returns stats of the container. If the container does not // exist, the call returns an error. ContainerStats(ctx context.Context, in *ContainerStatsRequest, opts ...grpc.CallOption) (*ContainerStatsResponse, error) // ListContainerStats returns stats of all running containers. ListContainerStats(ctx context.Context, in *ListContainerStatsRequest, opts ...grpc.CallOption) (*ListContainerStatsResponse, error) // UpdateRuntimeConfig updates the runtime configuration based on the given request. UpdateRuntimeConfig(ctx context.Context, in *UpdateRuntimeConfigRequest, opts ...grpc.CallOption) (*UpdateRuntimeConfigResponse, error) // Status returns the status of the runtime. Status(ctx context.Context, in *StatusRequest, opts ...grpc.CallOption) (*StatusResponse, error) }
Container Runtime is responsible to implement RuntimeServiceServer
// RuntimeServiceServer is the server API for RuntimeService service. type RuntimeServiceServer interface { // Version returns the runtime name, runtime version, and runtime API version. Version(context.Context, *VersionRequest) (*VersionResponse, error) // RunPodSandbox creates and starts a pod-level sandbox. Runtimes must ensure // the sandbox is in the ready state on success. RunPodSandbox(context.Context, *RunPodSandboxRequest) (*RunPodSandboxResponse, error) // StopPodSandbox stops any running process that is part of the sandbox and // reclaims network resources (e.g., IP addresses) allocated to the sandbox. // If there are any running containers in the sandbox, they must be forcibly // terminated. // This call is idempotent, and must not return an error if all relevant // resources have already been reclaimed. kubelet will call StopPodSandbox // at least once before calling RemovePodSandbox. It will also attempt to // reclaim resources eagerly, as soon as a sandbox is not needed. Hence, // multiple StopPodSandbox calls are expected. StopPodSandbox(context.Context, *StopPodSandboxRequest) (*StopPodSandboxResponse, error) // RemovePodSandbox removes the sandbox. If there are any running containers // in the sandbox, they must be forcibly terminated and removed. // This call is idempotent, and must not return an error if the sandbox has // already been removed. RemovePodSandbox(context.Context, *RemovePodSandboxRequest) (*RemovePodSandboxResponse, error) // PodSandboxStatus returns the status of the PodSandbox. If the PodSandbox is not // present, returns an error. PodSandboxStatus(context.Context, *PodSandboxStatusRequest) (*PodSandboxStatusResponse, error) // ListPodSandbox returns a list of PodSandboxes. ListPodSandbox(context.Context, *ListPodSandboxRequest) (*ListPodSandboxResponse, error) // CreateContainer creates a new container in specified PodSandbox CreateContainer(context.Context, *CreateContainerRequest) (*CreateContainerResponse, error) // StartContainer starts the container. StartContainer(context.Context, *StartContainerRequest) (*StartContainerResponse, error) // StopContainer stops a running container with a grace period (i.e., timeout). // This call is idempotent, and must not return an error if the container has // already been stopped. // TODO: what must the runtime do after the grace period is reached? StopContainer(context.Context, *StopContainerRequest) (*StopContainerResponse, error) // RemoveContainer removes the container. If the container is running, the // container must be forcibly removed. // This call is idempotent, and must not return an error if the container has // already been removed. RemoveContainer(context.Context, *RemoveContainerRequest) (*RemoveContainerResponse, error) // ListContainers lists all containers by filters. ListContainers(context.Context, *ListContainersRequest) (*ListContainersResponse, error) // ContainerStatus returns status of the container. If the container is not // present, returns an error. ContainerStatus(context.Context, *ContainerStatusRequest) (*ContainerStatusResponse, error) // UpdateContainerResources updates ContainerConfig of the container. UpdateContainerResources(context.Context, *UpdateContainerResourcesRequest) (*UpdateContainerResourcesResponse, error) // ReopenContainerLog asks runtime to reopen the stdout/stderr log file // for the container. This is often called after the log file has been // rotated. If the container is not running, container runtime can choose // to either create a new log file and return nil, or return an error. // Once it returns error, new container log file MUST NOT be created. ReopenContainerLog(context.Context, *ReopenContainerLogRequest) (*ReopenContainerLogResponse, error) // ExecSync runs a command in a container synchronously. ExecSync(context.Context, *ExecSyncRequest) (*ExecSyncResponse, error) // Exec prepares a streaming endpoint to execute a command in the container. Exec(context.Context, *ExecRequest) (*ExecResponse, error) // Attach prepares a streaming endpoint to attach to a running container. Attach(context.Context, *AttachRequest) (*AttachResponse, error) // PortForward prepares a streaming endpoint to forward ports from a PodSandbox. PortForward(context.Context, *PortForwardRequest) (*PortForwardResponse, error) // ContainerStats returns stats of the container. If the container does not // exist, the call returns an error. ContainerStats(context.Context, *ContainerStatsRequest) (*ContainerStatsResponse, error) // ListContainerStats returns stats of all running containers. ListContainerStats(context.Context, *ListContainerStatsRequest) (*ListContainerStatsResponse, error) // UpdateRuntimeConfig updates the runtime configuration based on the given request. UpdateRuntimeConfig(context.Context, *UpdateRuntimeConfigRequest) (*UpdateRuntimeConfigResponse, error) // Status returns the status of the runtime. Status(context.Context, *StatusRequest) (*StatusResponse, error) }
Let’s check cri-o’s source code to understand how it can happen. The logic is similar in docker.
It has a server which implements RuntimeServiceServer.
// Server implements the RuntimeService and ImageService type Server struct { config libconfig.Config seccompProfile *seccomp.Seccomp stream StreamService netPlugin ocicni.CNIPlugin hostportManager hostport.HostPortManager
At the end of the chain, container runtime executes the command in the worker node.
// ExecContainer prepares a streaming endpoint to execute a command in the container. func (r *runtimeOCI) ExecContainer(c *Container, cmd []string, stdin io.Reader, stdout, stderr io.WriteCloser, tty bool, resize <-chan remotecommand.TerminalSize) error { processFile, err := prepareProcessExec(c, cmd, tty) if err != nil { return err } defer os.RemoveAll(processFile.Name())
args := []string{rootFlag, r.root, "exec"} args = append(args, "--process", processFile.Name(), c.ID()) execCmd := exec.Command(r.path, args...) if v, found := os.LookupEnv("XDG_RUNTIME_DIR"); found { execCmd.Env = append(execCmd.Env, fmt.Sprintf("XDG_RUNTIME_DIR=%s", v)) } var cmdErr, copyError error if tty { cmdErr = ttyCmd(execCmd, stdin, stdout, resize) } else { if stdin != nil { // Use an os.Pipe here as it returns true *os.File objects. // This way, if you run 'kubectl exec <pod> -i bash' (no tty) and type 'exit', // the call below to execCmd.Run() can unblock because its Stdin is the read half // of the pipe. r, w, err := os.Pipe() if err != nil { return err } go func() { _, copyError = pools.Copy(w, stdin) }()
execCmd.Stdin = r } if stdout != nil { execCmd.Stdout = stdout } if stderr != nil { execCmd.Stderr = stderr }
cmdErr = execCmd.Run() }
if copyError != nil { return copyError } if exitErr, ok := cmdErr.(*exec.ExitError); ok { return &utilexec.ExitErrorWrapper{ExitError: exitErr} } return cmdErr }
“Il fiore perfetto è una cosa rara. Se si trascorresse la vita a cercarne uno, non sarebbe una vita sprecata.”
Un meraviglioso scontro-confronto tra due paradigmi di esistenza, uno che si fonda nel suo dinamismo, fretta, programmazione, efficienza e l’altro che cerca il fiore perfetto in ogni bocciolo, consapevole che ogni bocciolo morirà eppure conscio che la sua esistenza sarà compiuta, breve ed unica. Una bellezza aleatoria, non governabile, non gestibile. Io che sono sempre stato espressione del primo pensiero nei minimi dettagli sono sempre più attratto dal secondo e sorrido rispetto alle motivazioni dell’efficienza e della programmazione perchè puoi adottare qualsiasi metodologia ma il carburante del successo è sentirsi parte di un qualcosa che in fondo ami/curi/credi in qualche modo.
La bellezza del fiore nel momento in cui lo vedi. Man mano riesco a far mio questo concetto, spingendomi a pensare al “cambiamento” in maniera diversa perché in fondo tutto cambia, il fiore muore e sta morendo anche nel momento di massima bellezza. Io non sono quello di dieci anni fa ma sopratutto anche le persone intorno a me cambiano, in maniera più o meno percettibile.
I bambini ad esempio cambiano ad una velocità per me difficile da accettare : ancora vorrei fare le coccole alla mia piccolina, fare l’aeroplano con il cucchiaino, ma ormai la piccolina non c’è più e anche se mi manca devo capire che quello che è stato è compiuto ed è stato bellissimo e lavorare su una nuova bellezza che se pur diversa è meravigliosa. Riconoscerla. Adesso posso parlarle delle mie paure ad esempio, delle sue, della bellezza di un tramonto.
Amarsi in maniera diversa ma sempre amarsi. Io questa cosa non l’avevo mica capita sai ? E’ importante compiersi e crescere amando sempre ma in modo diverso. Non rimpiangere niente. Nel passato non c’è niente che una lezione per vivere la bellezza dell’adesso. Adesso sei felice ? Cosa c’è stato di bello oggi ? Cosa hai imparato ? Hai amato ? Sei cresciuto ? Cosa non farai domani ? Cosa lasci al passato ?
Mi esplode il cervello se penso di poter essere ogni cosa, una qualunque parte del tutto. Il non-pensiero salda il corpo con lo spirito e libera dalla paura della morte. Ah se ho avuto paura della morte io !
Cambio il modo di vedere: i germogli non sono “nel fiore della vita”, ma stanno tutti morendo. È proprio in questa idealizzazione estetica della morte che si può riconoscere la vita “in ogni respiro, in ogni tazza di te e in ogni vita che togliamo: la via del guerriero”.
A tutte le persone che amano qualcuno che non hanno mai visto, a tutte le persone che amano ma non sono ricambiate, o non ancora. Continuate ad amare, e siate felici solo di questo. Amare è desiderare la felicità dell’altro, e anche se non dovesse andare come volete voi, nessuno potrà togliervi il vostro amore, che è la cosa più preziosa e vera che avete. Siate felici di amare: magari un giorno andrà bene, ma se non dovesse succedere siate felici perché l’altra persona è felice. Non sarà difficile se amate davvero. E non perdete le speranze, perché avete già tutto ciò di cui avete bisogno. A tutte le persone che amano, me compreso